SQL
Def et Utilité :
De nombreuses déclinaisons existent :
- SQLite
- MySQL
- Postgres
- Oracle
- Microsoft SQL Server
Mais alors c'est quoi une base de donnée relationnelle ?
C'est une collection de feuilles excel liés en elles. Les feuilles ont un nombre de colonnes et de lignes définit.
Voici un exemple de table :
| Id | Make/Model | # Wheels | # Doors | Type |
|---|---|---|---|---|
| 1 | Ford Focus | 4 | 4 | Sedan |
| 2 | Tesla Roadster | 4 | 2 | Sports |
| 3 | Kawakasi Ninja | 2 | 0 | Motorcycle |
| 4 | McLaren Formula 1 | 4 | 0 | Race |
| 5 | Tesla S | 4 | 4 | Sedan |
Documentation :
Cette documentation suit l'apprentissage de ce site :
https://sqlbolt.com/
SELECT :
SELECT column, another_column, … FROM mytable;
sert à sélectionner des données spécifiques d'une base de données. Voici ce que fait chaque partie de la requête :
SELECT column, another_column, ...: Cette partie spécifie les colonnes à extraire de la table. Vous pouvez lister autant de colonnes que vous le souhaitez, ou utiliser*pour sélectionner toutes les colonnes, par exemple :SELECT * FROM mytable;
- `FROM mytable` : Indique la table à partir de laquelle les données doivent être extraites. Ici, les données sont extraites de la table appelée `mytable`.
### Contraintes :
----
Les contraintes permettent de filtrer nos résultats de manière plus précise :
```SQL
SELECT column, another_column, … FROM mytable WHERE condition AND/OR _another_condition_ AND/OR …;
-
WHERE condition: Cette clause est utilisée pour définir des conditions qui doivent être remplies pour qu'un enregistrement soit inclus dans les résultats retournés. Les conditions peuvent être basées sur les valeurs des colonnes, des comparaisons, des expressions, etc. -
AND/OR another_condition: Vous pouvez ajouter plusieurs conditions en utilisant les opérateursANDetORpour affiner davantage les résultats :ANDest utilisé pour s'assurer que toutes les conditions liées avecANDdoivent être vraies pour qu'un enregistrement soit inclus dans les résultats.ORsignifie que si l'une des conditions liées avecORest vraie, l'enregistrement sera inclus dans les résultats
Il est possible de complexifier encore les requêtes :
| Operator | Condition | SQL Example |
|---|---|---|
| =, !=, < <=, >, >= | Standard numerical operators | col_name != 4 |
| BETWEEN … AND … | Number is within range of two values (inclusive) | col_name BETWEEN 1.5 AND 10.5 |
| NOT BETWEEN … AND … | Number is not within range of two values (inclusive) | col_name NOT BETWEEN 1 AND 10 |
| IN (…) | Number exists in a list | col_name IN (2, 4, 6) |
| NOT IN (…) | Number does not exist in a list | col_name NOT IN (1, 3, 5) |
| Par exemple : |
SELECT name, age
FROM users
WHERE age >= 18
AND (name = 'Alice' OR name = 'Bob');
Comment faire des recherches de text précises ?
| Operator | Condition | Example |
|---|---|---|
| = | Case sensitive exact string comparison (notice the single equals) | col_name = "abc" |
| != or <> | Case sensitive exact string inequality comparison | col_name != "abcd" |
| LIKE | Case insensitive exact string comparison | col_name LIKE "ABC" |
| NOT LIKE | Case insensitive exact string inequality comparison | col_name NOT LIKE "ABCD" |
| % | Used anywhere in a string to match a sequence of zero or more characters (only with LIKE or NOT LIKE) | col_name LIKE "%AT%" (matches "AT", "ATTIC", "CAT" or even "BATS") |
| _ | Used anywhere in a string to match a single character (only with LIKE or NOT LIKE) | col_name LIKE "AN_" (matches "AND", but not "AN") |
| IN (…) | String exists in a list | col_name IN ("A", "B", "C") |
| NOT IN (…) | String does not exist in a list | col_name NOT IN ("D", "E", "F") |
| Exemple : |
SELECT * FROM movies WHERE title LIKE "toy story%";
DISTINCT :
DISTINCT a pour but de supprimer des résultats les doublons :
SELECT DISTINCT column, another_column, … FROM mytable WHERE _condition(s)_;
SELECT DISTINCT column, another_column, ...: Cette partie de la requête indique que vous souhaitez récupérer des valeurs uniques pour les colonnes spécifiées. L'usage deDISTINCTgarantit que chaque combinaison de valeurs dans les colonnes sélectionnées apparaîtra une seule fois dans les résultats. Si des doublons existent dans les données, ils seront filtrés pour ne présenter que des entrées uniques.
ORDER BY :
ORDER BY a pour but de mettre en ordre les résultats selon un critère.
SELECT column, another_column, … FROM mytable WHERE _condition(s)_ ORDER BY column ASC/DESC;
ORDER BY column ASC/DESC: Cette clause est utilisée pour trier les résultats selon les valeurs d'une colonne spécifique.ASCindique que les résultats doivent être triés en ordre croissant (de la plus petite à la plus grande valeur).DESCindique que les résultats doivent être triés en ordre décroissant (de la plus grande à la plus petite valeur).
ORDER BY est souvent utilisé avec LIMIT et OFFSET.
SELECT column, another_column, … FROM mytable WHERE _condition(s)_ ORDER BY column ASC/DESC LIMIT num_limit OFFSET num_offset;
ORDER BY column ASC/DESC: Trie les résultats par une colonne spécifique, soit en ordre croissant (ASC) soit en ordre décroissant (DESC).LIMIT num_limit: Limite le nombre d'enregistrements renvoyés ànum_limit. Cela est utile pour contrôler le volume de données renvoyé, particulièrement dans les contextes de pagination ou lorsque les ensembles de données sont très grands.OFFSET num_offset: Spécifie le nombre d'enregistrements à sauter avant de commencer à renvoyer les résultats. C'est également une fonctionnalité courante dans les systèmes de pagination, permettant aux utilisateurs de sauter à une page spécifique de résultats.
Exemple :
SELECT title FROM movies
ORDER BY title ASC
LIMIT 5 OFFSET 5;
JOIN :
Le but de join est de travailler et récupérer des résultats sur plusieurs fiches SQL .
INNER JOIN :
SELECT column, another_table_column, … FROM mytable INNER JOIN another_table ON mytable.id = another_table.id WHERE _condition(s)_ ORDER BY column, … ASC/DESC LIMIT num_limit OFFSET num_offset;
- FROM mytable : Indique la table principale à partir de laquelle la requête commence à collecter les données, ici nommée
mytable - INNER JOIN another_table ON mytable.id = another_table.id : Ceci effectue une jointure interne entre
mytableetanother_table. Les données sont combinées en fonction des lignes où l'identifiant (id) dansmytablecorrespond à l'identifiant dansanother_table. Ce type de jointure renvoie uniquement les lignes ayant une correspondance dans les deux tables.
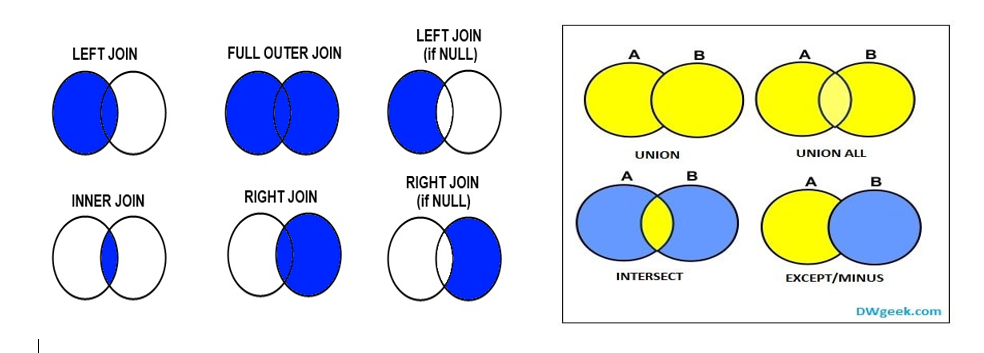
LEFT JOIN, RIGHT JOIN, FULL JOIN :
Ces mots clés sont utiles pour les tables qui sont asymétriques et ne possèdent pas de mot clé en commun.
SELECT column, another_column, … FROM mytable INNER/LEFT/RIGHT/FULL JOIN another_table ON mytable.id = another_table.matching_id WHERE _condition(s)_ ORDER BY column, … ASC/DESC LIMIT num_limit OFFSET num_offset;
- INNER/LEFT/RIGHT/FULL JOIN another_table ON mytable.id = another_table.matching_id :
- Cette instruction réalise une jointure entre
mytableetanother_table. Le type de jointure (INNER, LEFT, RIGHT, FULL) affecte les résultats :- INNER JOIN : Renvoie les lignes où il existe une correspondance dans les deux tables.
- LEFT JOIN : Renvoie toutes les lignes de la première table (
mytable), et les correspondances de la deuxième table (another_table). Si aucune correspondance n'est trouvée, les résultats contiendrontNULLpour les colonnes de la deuxième table. - RIGHT JOIN : Renvoie toutes les lignes de la deuxième table (
another_table), et les correspondances de la première table (mytable). Si aucune correspondance n'est trouvée, les résultats contiendrontNULLpour les colonnes de la première table. - FULL JOIN : Combine les résultats des jointures LEFT et RIGHT. Renvoie toutes les lignes de
mytableetanother_table, avec les correspondances quand elles existent etNULLautrement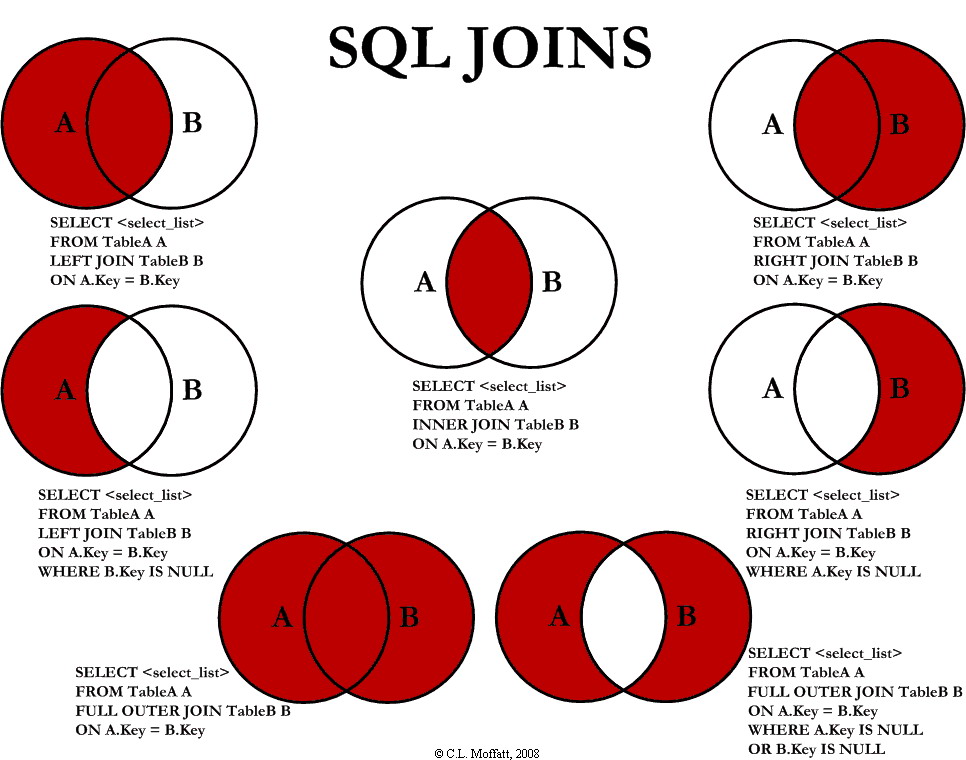
- Cette instruction réalise une jointure entre
NULL VALUE :
Il faut éviter autant que faire ce peut les value NULL qui peuvent empêcher l'exploitation des données.
SELECT column, another_column, … FROM mytable WHERE column IS/IS NOT NULL AND/OR _another_condition_ AND/OR …;
- WHERE column IS/IS NOT NULL :
- Cette condition filtre les lignes basées sur la présence ou l'absence de valeurs dans la colonne spécifiée.
IS NULLsera utilisé pour trouver les lignes où la colonne spécifiée contient une valeur NULL (c'est-à-dire, aucun donnée), tandis queIS NOT NULLpermet de trouver les lignes où la colonne contient une valeur non-NULL.
- Cette condition filtre les lignes basées sur la présence ou l'absence de valeurs dans la colonne spécifiée.
Expressions :
Les expressions permettent d'intégrer une logique mathématique pour transformer les valeurs reçues par exemple.
SELECT particle_speed / 2.0 AS half_particle_speed FROM physics_data WHERE ABS(particle_position) * 10.0 > 500;
- SELECT particle_speed / 2.0 AS half_particle_speed :
- Cette partie de la requête calcule la moitié de la vitesse des particules.
particle_speedest probablement une colonne dans la tablephysics_dataqui contient la vitesse de chaque particule. La vitesse est divisée par 2.0 pour obtenir la moitié de cette valeur. AS half_particle_speedest un alias utilisé pour nommer la colonne résultante dans le jeu de résultats. Cela signifie que dans les résultats de la requête, cette colonne calculée sera étiquetée commehalf_particle_speedau lieu d'une expression.
- Cette partie de la requête calcule la moitié de la vitesse des particules.
- FROM physics_data :
- Spécifie que la table d'où proviennent les données est
physics_data. Cette table contient des informations relatives à des particules, y compris leur vitesse (particle_speed) et probablement d'autres paramètres physiques.
- Spécifie que la table d'où proviennent les données est
- WHERE ABS(particle_position) * 10.0 > 500 :
- Cette clause
WHEREfiltre les lignes incluses dans les résultats finaux basée sur la condition donnée.ABS(particle_position)applique la fonctionABS, qui retourne la valeur absolue departicle_position.particle_positionest vraisemblablement une autre colonne dephysics_dataqui indique la position de chaque particule. - La condition multiplie la valeur absolue de la position de la particule par 10.0 et inclut seulement les lignes où ce produit est supérieur à 500. Cela signifie que la requête sélectionne les particules dont la position, indépendamment du signe (+ ou -), et après multiplication par 10, dépasse 500 en valeur absolue.
- Cette clause
Aggregates :
- SELECT AGG_FUNC(column_or_expression) AS aggregate_description,
- AGG_FUNC(column_or_expression) :
AGG_FUNCest un placeholder pour une fonction d'agrégation, telle queSUM,AVG(moyenne),MAX,MIN,COUNT, etc. Ces fonctions sont utilisées pour effectuer un calcul sur un ensemble de valeurs (généralement une colonne) et produire un résultat unique. Par exemple,SUM(column)additionnerait toutes les valeurs de la colonne spécifiée. - column_or_expression : Indique la colonne ou l'expression sur laquelle la fonction d'agrégation est appliquée. Cela peut être simplement le nom d'une colonne ou une expression plus complexe impliquant une ou plusieurs colonnes.
- AS aggregate_description : Fournit un alias pour la colonne de résultat de l'agrégation, facilitant la référence à cette colonne dans des traitements ultérieurs ou dans les résultats de sortie. Par exemple, si vous utilisez
SUM(salary) AS total_salary,total_salaryserait l'alias de la somme des salaires.
Les fonctions aggrégées sont un peu comme les fonctions EXCEL :
- AGG_FUNC(column_or_expression) :
| Function | Description |
|---|---|
| COUNT(*), **COUNT(column) | A common function used to counts the number of rows in the group if no column name is specified. Otherwise, count the number of rows in the group with non-NULL values in the specified column. |
| MIN(column) | Finds the smallest numerical value in the specified column for all rows in the group. |
| MAX(column) | Finds the largest numerical value in the specified column for all rows in the group. |
| **AVG(**column) | Finds the average numerical value in the specified column for all rows in the group. |
| SUM(column) | Finds the sum of all numerical values in the specified column for the rows in the group. |
Grouped Aggregate :
SELECT AGG_FUNC(_column_or_expression_) AS aggregate_description, … FROM mytable WHERE _constraint_expression_ GROUP BY column;
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …:AGG_FUNC(column_or_expression)représente une fonction d'agrégation appliquée à une colonne ou une expression spécifique. Les fonctions d'agrégation courantes incluentSUM(),AVG(),MAX(),MIN(), etCOUNT().AS aggregate_descriptionpermet de renommer le résultat de la fonction d'agrégation pour une utilisation plus simple dans les résultats de la requête.
Exemple :
SELECT AVG(salary) AS average_salary FROM employees WHERE department = 'Sales' GROUP BY region;
SELECT role, AVG(years_employed) as Average_years_employed
FROM employees
GROUP BY role;
group_by_column: une colonne selon laquelle les données seront regroupées. Cette colonne est souvent celle utilisée dans la clauseGROUP BY.AGG_FUNC(column_expression): une fonction d'agrégation appliquée à une colonne ou une expression. Comme expliqué précédemment, il peut s'agir de fonctions telles queSUM(),AVG(),MAX(),MIN(), etCOUNT().AS aggregate_result_alias: permet de renommer le résultat de la fonction d'agrégation pour simplifier les références dans les résultats de la requête.GROUP BY column:- Les lignes qui passent le filtre
WHEREsont ensuite regroupées par les valeurs dans la colonne spécifiée. L'agrégation est calculée pour chaque groupe.
- Les lignes qui passent le filtre
HAVING group_condition:- Après que les données ont été regroupées et les agrégations calculées,
HAVINGest utilisé pour filtrer ces groupes. Contrairement àWHEREqui filtre les lignes,HAVINGfiltre les groupes basés sur le résultat de l'agrégation.
- Après que les données ont été regroupées et les agrégations calculées,
HAVING et GROUP BY :
SELECT group_by_column, AGG_FUNC(_column_expression_) AS aggregate_result_alias, … FROM mytable WHERE _condition_ GROUP BY column **HAVING _group_condition_**;
Ordre d'execution :
SELECT DISTINCT column, AGG_FUNC(_column_or_expression_), … FROM mytable JOIN another_table ON mytable.column = another_table.column WHERE _constraint_expression_ GROUP BY column HAVING _constraint_expression_ ORDER BY _column_ ASC/DESC LIMIT _count_ OFFSET _COUNT_;
FROM:- C'est la première étape de l'exécution. SQL détermine d'abord quelle(s) table(s) est/sont impliquée(s) dans la requête.
JOIN(si présent) :- Si la requête implique des jointures entre plusieurs tables, elles sont résolues après la spécification des tables dans la clause
FROM.
- Si la requête implique des jointures entre plusieurs tables, elles sont résolues après la spécification des tables dans la clause
WHERE:- Cette clause filtre les lignes avant tout regroupement, agrégation, ou tri. Seules les lignes qui satisfont la condition spécifiée sont inclues dans les étapes suivantes.
GROUP BY:- Après le filtrage initial, les lignes restantes sont regroupées en fonction des valeurs des colonnes spécifiées dans cette clause.
AGGREGATION:- Les fonctions d'agrégation (comme
SUM,AVG,COUNT, etc.) sont appliquées aux groupes formés par la clauseGROUP BY.
- Les fonctions d'agrégation (comme
HAVING:- Cette clause filtre les groupes formés en fonction des résultats des fonctions d'agrégation. Contrairement à
WHERE,HAVINGopère après l'agrégation.
- Cette clause filtre les groupes formés en fonction des résultats des fonctions d'agrégation. Contrairement à
SELECT:- Les colonnes ou expressions spécifiées sont sélectionnées et préparées pour la sortie. Cela inclut les colonnes directes, les expressions et les résultats des fonctions d'agrégation.
DISTINCT(si présent) :- Si spécifié, cette opération élimine les doublons dans les résultats après le traitement de
SELECT.
- Si spécifié, cette opération élimine les doublons dans les résultats après le traitement de
ORDER BY:- Cette étape trie les résultats finaux selon les colonnes ou critères spécifiés. C'est une des dernières étapes avant que les données soient retournées à l'utilisateur.
LIMIT / OFFSET(si présent) :- Ces clauses limitent le nombre de lignes à retourner et déterminent à partir de quelle ligne commencer à retourner les résultats. Elles sont appliquées tout à la fin du traitement de la requête.
INSERT :
Certaines bases de données contiennent des templates, des shema qui définissent des types de données dans des champs.
INSERT INTO mytable VALUES (value_or_expr, another_value_or_expr, …), (value_or_expr_2, another_value_or_expr_2, …), …;
par exemple :
INSERT INTO boxoffice **(movie_id, rating, sales_in_millions)** VALUES (1, 9.9, 283742034 / 1000000);
Donc si on ne précise pas les champs tout est inséré dans l'ordre par défaut
UPDATE :
UPDATE mytable SET column = value_or_expr, other_column = another_value_or_expr, … WHERE condition;
Il faut faire très attention avec les requêtes update qui peuvent détruire des bases de données.
Exemple :
UPDATE movies
SET director = "John Lasseter"
WHERE id = 2;
DELETE :
Sert à supprimer des lignes dans une table :
DELETE FROM mytable WHERE condition;
CREATE TABLE :
CREATE TABLE IF NOT EXISTS mytable ( column _DataType_ _TableConstraint_ DEFAULT _default_value_, another_column _DataType_ _TableConstraint_ DEFAULT _default_value_, … );
CREATE TABLE IF NOT EXISTS mytable:CREATE TABLEest la commande pour créer une nouvelle table dans la base de données.IF NOT EXISTSest une condition qui vérifie si une table portant le même nom (mytabledans ce cas) existe déjà dans la base de données. Si c'est le cas, la commande n'aura aucun effet (i.e., la table ne sera pas recréée et aucune erreur ne sera générée). Si la table n'existe pas, alors elle sera créée selon la définition fournie.mytableest le nom de la nouvelle table à créer.
- Définition des colonnes :
- Chaque ligne après le nom de la table définit une colonne de la table. La syntaxe générale pour définir une colonne est :
column_name DataType TableConstraint DEFAULT default_value column_nameest le nom de la colonne.DataTypespécifie le type de données que la colonne stockera, par exempleINT,VARCHAR,DATE, etc.TableConstraint(optionnel) spécifie les contraintes appliquées à la colonne. Les contraintes de table courantes incluentPRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL, etc. Ces contraintes sont utilisées pour imposer certaines règles sur les données de la colonne pour maintenir l'intégrité et la logique des données.DEFAULT default_value(optionnel) définit une valeur par défaut pour la colonne. Si une valeur n'est pas spécifiée lors de l'insertion d'une ligne, la valeur par défaut sera utilisée.
Exemple :
- Chaque ligne après le nom de la table définit une colonne de la table. La syntaxe générale pour définir une colonne est :
CREATE TABLE IF NOT EXISTS employees ( id INT PRIMARY KEY, name VARCHAR(100) NOT NULL, salary DECIMAL(10, 2) DEFAULT 0.00 );
CREATE TABLE Database (
Name TEXT,
Version FLOAT,
Download_count INTEGER
);
Comment peut-on préciser quel type de données correspond à quel champ ?
| Data type | Description |
|---|---|
INTEGER, BOOLEAN |
The integer datatypes can store whole integer values like the count of a number or an age. In some implementations, the boolean value is just represented as an integer value of just 0 or 1. |
FLOAT, DOUBLE, REAL |
The floating point datatypes can store more precise numerical data like measurements or fractional values. Different types can be used depending on the floating point precision required for that value. |
CHARACTER(num_chars), VARCHAR(num_chars), TEXT |
The text based datatypes can store strings and text in all sorts of locales. The distinction between the various types generally amount to underlaying efficiency of the database when working with these columns. Both the CHARACTER and VARCHAR (variable character) types are specified with the max number of characters that they can store (longer values may be truncated), so can be more efficient to store and query with big tables. |
DATE, DATETIME |
SQL can also store date and time stamps to keep track of time series and event data. They can be tricky to work with especially when manipulating data across timezones. |
BLOB |
Finally, SQL can store binary data in blobs right in the database. These values are often opaque to the database, so you usually have to store them with the right metadata to requery them. |
| Il existe aussi d'autres contraintes que l'on peut créer, par exemple limiter un nombre à un maximum |
| Constraint | Description |
|---|---|
PRIMARY KEY |
This means that the values in this column are unique, and each value can be used to identify a single row in this table. |
AUTOINCREMENT |
For integer values, this means that the value is automatically filled in and incremented with each row insertion. Not supported in all databases. |
UNIQUE |
This means that the values in this column have to be unique, so you can't insert another row with the same value in this column as another row in the table. Differs from the PRIMARY KEY in that it doesn't have to be a key for a row in the table. |
NOT NULL |
This means that the inserted value can not be NULL. |
CHECK (expression) |
This allows you to run a more complex expression to test whether the values inserted are valid. For example, you can check that values are positive, or greater than a specific size, or start with a certain prefix, etc. |
FOREIGN KEY |
This is a consistency check which ensures that each value in this column corresponds to another value in a column in another table. For example, if there are two tables, one listing all Employees by ID, and another listing their payroll information, the FOREIGN KEY can ensure that every row in the payroll table corresponds to a valid employee in the master Employee list. |
ALTER TABLE :
ADD :
ALTER TABLE mytable ADD column _DataType_ _OptionalTableConstraint_ DEFAULT default_value;
ALTER TABLE mytable:ALTER TABLEest la commande utilisée pour modifier la structure d'une table existante dans la base de données.mytableest le nom de la table à modifier.
ADD column DataType OptionalTableConstraint DEFAULT default_value:
ADDest l'instruction qui spécifie que vous souhaitez ajouter quelque chose à la table, dans ce cas, une nouvelle colonne.columnest le nom de la nouvelle colonne à ajouter.DataTypedéfinit le type de données que la colonne va stocker (par exemple,INT,VARCHAR,DATE, etc.).OptionalTableConstraint(facultatif) indique toute contrainte que vous souhaitez appliquer à cette colonne, commeNOT NULL,UNIQUE,PRIMARY KEY, etc. Ces contraintes aident à maintenir l'intégrité des données dans la table.DEFAULT default_value(facultatif) est utilisé pour définir une valeur par défaut pour la colonne. Si une valeur pour cette colonne n'est pas fournie lors de l'insertion d'une nouvelle ligne, la valeur par défaut sera utilisée automatiquement.
Exemple :
ALTER TABLE movies ADD Aspect_ration FLOAT
DROP :
ALTER TABLE mytable DROP column_to_be_deleted;
RENAME :
ALTER TABLE mytable RENAME TO new_table_name;
DROP TABLE :
Drop table supprime une table, toutes ses données, métadonnées, et le schéma de la table :
DROP TABLE IF EXISTS mytable;
UNION :
La commande union permet de mettre bout à bout des requêtes SQL.
SELECT * FROM table1
UNION
SELECT * FROM table2
Commandes avancées :
DATABASE(): permet d'afficher le nom de la databaseVERSION(): donne la version de la databaseCURRENT_USER(): utilisateur courantSELECT * FROM information_schema.tables: lister les tables dans la base de donnéeSELECT * FROM information_schema.columns: lister les colonnesMD5(): converti en md5 un résultat.SLEEP(): met le site en attente pdt x secondesLENGTH(): obtient la longueur d'une chaine de charactères
Exemples :
Cette section est dédiée à des exemples de requêtes sympa pour en apprendre plus sur la syntaxe.
SELECT city, longitude FROM north_american_cities
WHERE longitude < -87.629798
ORDER BY longitude ASC;
SELECT title, domestic_sales, international_sales, rating
FROM movies
JOIN boxoffice
ON movies.id = boxoffice.movie_id
WHERE domestic_sales <= international_sales
ORDER BY rating DESC;
SELECT title, year
FROM movies
JOIN boxoffice
ON movies.id = boxoffice.movie_id
WHERE year % 2 = 0;
SELECT role, AVG(years_employed) as Average_years_employed
FROM employees
GROUP BY role;
SELECT director, SUM(domestic_sales + international_sales) as Cumulative_sales_from_all_movies
FROM movies
INNER JOIN boxoffice
ON movies.id = boxoffice.movie_id
GROUP BY director;