Reverse Engineering
Intro :
Le reverse Engineering (RE) est la pratique qui vise à exploiter des fichiers binaires.
Je me base sur ce site pour toutes les fiches liées à ce sujet :
https://guyinatuxedo.github.io/
Autre ressources utiles :
https://www.reddit.com/r/HowToHack/comments/112hcj9/what_are_some_good_resources_to_learn_about/
Exploitation de fichiers binaires :
Les programmes ne sont pas directement executés dans les langages compilés (C, C++, pas python par exemple), un fichier binaire est créé et c'est celui ci qui est executé. C'est généralement avec un compilateur que ces fichiers binaires sont générés, qui transforment les instructions humaines (le code) en instruction machine.
Notre objectif sera de trouver les failles de ses fichiers pour les exploiter, généralement en comprenant la logique interne de ces fichiers pour les détourner.
Reverse Engineering :
Le RE est le process de retrouver comment quelque chose fonctionne, dans notre usage afin de l'exploiter.
Méthode :
Cette fiche contient une liste de commandes et bonnes pratiques a utiliser pour analyser un fichier et cela en fonction de son type, de son contenu etc.
Première approche :
Notre premier objectif est d'aborder le fichier et de comprendre un peu sa structure en obtenant des premières informations.
En premier lieu nous voulons identifier le type de fichier que nous possédons et la meilleur manière de le faire est d'utiliser la commande file.
file <file>
On va ensuite utiliser binwalk pour obtenir plus d'informations au besoin.
On peut ensuite utiliser Strings ce qui permet de chercher des chaîne de charactères en clair dans le fichier binaire.
Enfin si on veut une première approche encore plus précise on peut déjà ouvrir Binary Ninja et aller dans triage summary. On retrouvera toutes les informations précédentes avec des informations supplémentaires sur les imports/exports des fichiers.
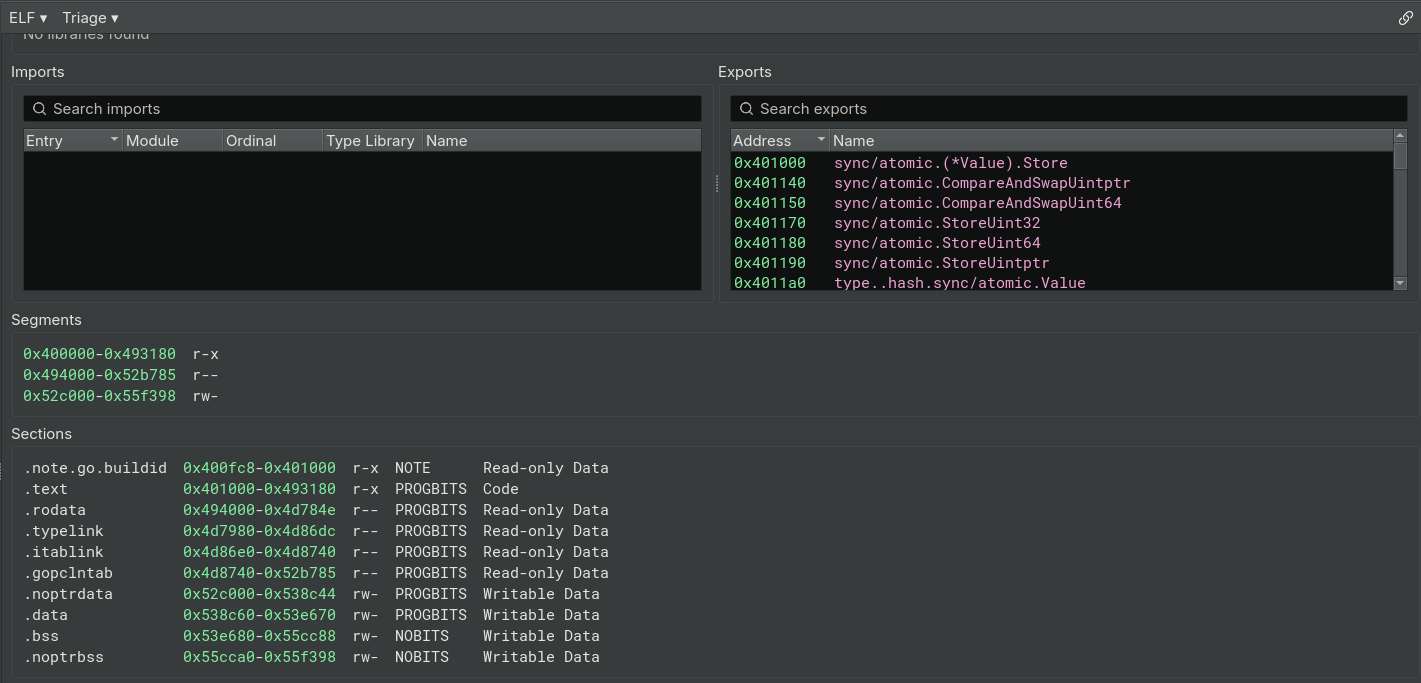
Seconde approche :
Maintenant que l'on connait le type de fichier que l'on va aborder on peut plonger dans plus de détails et commencer à aborder des outils spécifiques.
Aussi avant de passer aux outils, il faut comprendre que l'on a 3 types d'analyses possibles pour les fichiers (la 3eme étant optionnelles et à utiliser dans des cas très particuliers).
Analyse Statique :
Ma technique générale pour faire une analyse statique est d'essayer d'abord de nettoyer le code en changeant le nom des variables et en mettant des commentaires sur les fonctions etc.
Aussi il me semble essentiel, de regarder rapidement ce que font les fonctions en pseudo code de haut niveau, pour ensuite au cas par cas regarder dans le code assembleur ce qui se passe en détail.
Cela permet de gagner du temps pour les fonctions évidentes et de se focaliser sur les fonctions les plus complexes.
Dans de nombreux fichiers, les données sensibles sont cachée, c'est à dire que si il y a des mots de passe ils ne sont pas stockés en clair, mais déchiffrés lors du fonctionnement du code. Aussi les adresses de ces informtations sont bien souvents obtenues de manières contournée pour rendre le code le plus obfusqué possible.
Exemple :

Dans ce cas on place une adresse dans une variable puis on soustrait une valeur à celle-ci et on la met dans le stack pour y accéder plus tard.
Cette méthode bien que très simple démontre clairement que toutes les valeurs ne sont pas accédées directement mais souvent avec des contournement pour rendre la tâches plus complexe.
Bien souvent aussi, des manières peu communes sont utilisées pour rendre la lecture plus dure, en faisant des affectations à des registre et en les utilisant plus tard. Il faut donc être toujours très vigilant et ne pas oublier que chaque instruction en assembleur est utile.
Aussi si cette analyse ne fonctionne pas on peut passer à la suite (attention les deux types d'analyses fonctionnent mieux en parallèle en passant de l'une à l'autre pour éclaircir les mystères du code.)
Analyse Dynamique :
L'analyse dynamique si bien réalisée permet de comprendre le fonctionnement du programme en profondeur, en observant le flow de celui-ci et en observant les attributions qui sont faites dans les stack. Pour cela je recommande principalement GDB et son extension pour le rendre encore plus performant et plus clair.
Parfois de méthodes sont mises en place pour empêcher le debug des applications en détectant la présence d'un débugger ou non et il est donc nécessaire de les détecter lors de la première étapte.
Exemple :
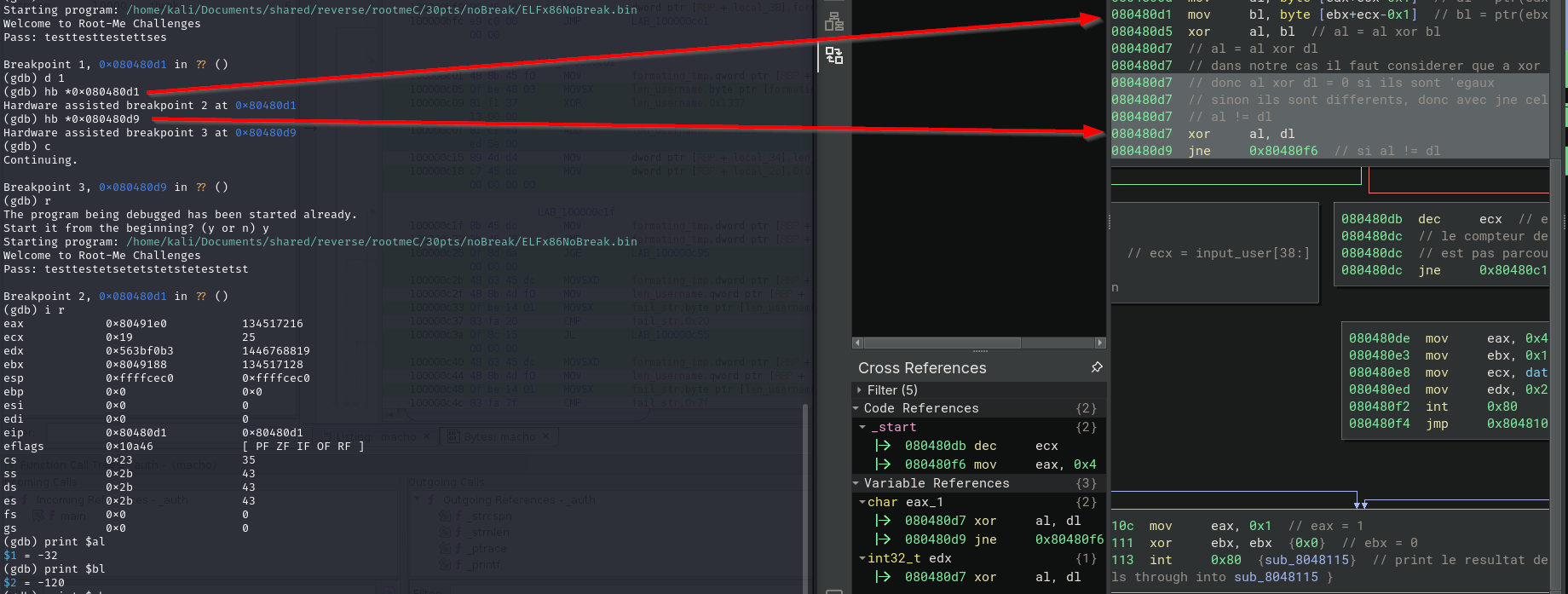
Dans ce challenge une détection des breakpoints avait lieu, il était donc nécessaire de patcher notre binaire ou bien de créer des breakpoints hardware afin de pouvoir l'analyser.
Analyse Symbolique :
Une dernière approche moins connue et bien plus spécifique existe. Celle-ci fonctionne particulièrement bien sur des fichiers simples avec peu d'embranchement. Pour cette approche j'utilise Angr et les détails seront laissés à cette fiche.
Outils & méthodes :
ELF :
Ce type de fichier executable est utilisé dans les OS de type UNIX de manière très large.
- GHIDRA
- Binary Ninja
- GDB
Dans le cas d'un fichier ARM il est possible de le débugger avec soit une Azure Virtual Machine ou bien en faisant une VM de raspberry PI par exemple.
PE :
On retrouve de nombreux types d'executables dans le Portable Executable et en fonction du type de création j'utilise des outils spécifiques.
PE .NET :
- DotPeek
- DNSpy
Autres :
APK :
Ici on a un fonctionnement un peu différent de l'analyse dynamique et statique. APK est un format de stockage de fichiers un peu comme un .zip, il convient donc d'abord d'extraire les fichiers APK avant de les analyser :
- APKtool :
apktool -d <file - JADX :
jadx-gui
En conjonction ces outils permettent d'anlyser aisément d'extraire pour faire une analyse statique les fichiers.
Aussi au besoin et pour une recherche plus approfondie après extraction j'utilise : - AndroidStudio